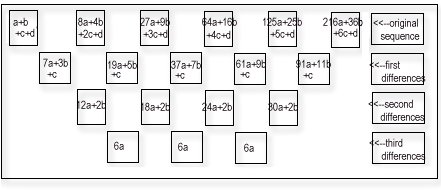
다시 알아보기로 한다.
제 6주 강의록은 영문으로 작성되었습니다.
국문강의록 보다 읽기가 조금 어렵기 때문에
여러분들은 천천히 읽고 학습하기 바랍니다.
Our fundamental goal is to efficiently determine the number of
elements in a set that possess none of a specified list of
properties or characteristics. We begin with several examples
to generate patterns that will lead to a generalization, extension,
and application.
EXAMPLE 1: Suppose there are 10 spectators at a ball
game and 4 are wearing caps. How many spectators are not
wearing caps?
|
Straightforward subtraction yields the result: 10 - 4 = 6. There
are 6 spectators not wearing caps. Let us introduce
mathematical notation that will, eventually, be helpful in
expressing a generalization of this result.
If we use T to represent all spectators and C to represent the
property "wearing a cap," we can apply conventional
mathematics notation to represent the number of items or
elements having the property: |T| = 10 and |C| = 4. We typically
use a slash over the top of the letter to represent the
complement of the property. [For this web page, we will use a
tilda (~) to represent the complement.] So ~C is the property
"not wearing a cap." This gives us |~C| = |T| - |C| = 10 - 4 = 6.
EXAMPLE 2: In the set S = {1,2,3,...,100}, how many elements
are not divisible by 3?
|
Let's use D to represent the set of values divisible by 3. From
the previous problem, it seems we need |~D| = |S| - |D|. We
know |S| = 100. The set D = {3,6,9,...,99} and it has 33
elements. We get |~D| = 100-33 = 67. Therefore, 67 elements
of S are not divisible by 3.
EXAMPLE 3: Among 10 students, 5 study mathematics, 6
study science, and 2 study both. How many of these students
study neither mathematics nor science?
|
For this problem, we first refer to a Venn diagram, a visual tool
we could have employed in the first two examples as well. In the
figure here we represent each property with a circle, and the
portion on the circles that overlap, or intersect, represents
elements with both the properties. We use T to represent the
entire group of students, M to represent the property "study
mathematics" and S to represent the property "study science."
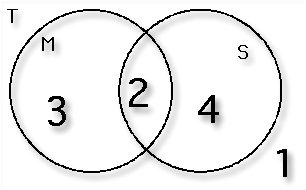
We know there are 2 people who study both mathematics and
science, so we place a 2 at the intersection of the two
properties (circles). We must then have 3 who study
mathematics but not science (because 5 in all study
mathematics), and 4 who study science but not mathematics
(because 6 in all study science). This accounts for 9 people, so
the remaining 1 person must study neither mathematics nor
science.
This is a relatively straightforward determination, especially with
the aid of the Venn diagram. How do our calculations compare
to those made in the first two examples? We have |T| = 10, |M| =
5, |S| = 6, and |M^S| = 2. [Note that on this web page we use ^ to
represent the intersection of two sets. Normally this is an
inverted U.]
But |~M^~S| is not equal to |T| - (|M| + |S|), a pattern we might
have tried based on the first two examples. Why is this
insufficient? Look back at the Venn diagram. When we subtract
|M| and |S| from |T|, we are twice subtracting the number of
elements in the intersection of the two sets. That is the value 2
here, or in general, |M^S|. To compensate for the "over"
subtraction, we add back |M^S|, as follows: |~M^~S| = |T| - (|M| +
S|) + |M^S|.
EXAMPLE 4: Among 18 students in a room, 7 study
mathematics, 10 study science, and 10 study computer
programming. Also, 3 study mathematics and science, 4 study
mathematics and computer programming, and 5 study science
and computer programming. We know that 1 student studies
all three subjects. How many of these students study none of
the three subjects?
|
We are looking for |~M^~S^~C|, where M, S, and C represent
belowing to the group that studies each of the three subjects
mathematics, science, and computer programming,
respectively. Consider the Venn diagram below. Can you justify
each entry in the diagram, starting from knowing that |M^S^C| =
1? How many students study none of the three subjects?
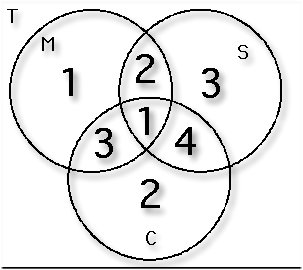
Trying to use and generalize the patterns we've established
above, consider |M| + |S| + |C|. What values are "over counted"
here? When we subtract |M ^ S| + |M ^ C| + |S ^ C| from |M| + |S|
+ |C| to compensate, what values are "over" subtracted? What
can be done to compensate for this?
EXAMPLE 5: Extend the patterns generated thus far in order
to solve the following problem. Draw a Venn diagram if
desired:
In a mathematics department of 40, faculty are members
represent four different professional organizations: NCTM (N),
MAA (M), AMS (A), and SSMA (S). We know that 21 are
members of NCTM, 26 are MAA members, 19 belong to
AMS, and 17 are in SSMA. In addition, we know that 15 are in
both NCTM and MAA, 6 are in NCTM and AMA, 9 are in
NCTM and SSMA, 14 and in MAA and AMS, 10 are in MAA
and SSMA, and 11 are in AMS and SSMA. We also know that
6 are in NCTM, MAA, and AMS, 5 are in NCTM, MAA, and
SSMA, 4 are in NCTM, AMS, and SSMA, and 9 are in MAA,
AMS, and SSMA. finally, 4 people belong to all four
organizations. How many faculty members belong to none of
these organizations?
|
EXAMPLE 6: Extend the patterns developed thus far to write
a general formula for determining the number of items in a set
that possess none of k properties maintained by the set. This
is the Inclusion-Exclusion Principle.
|
EXAMPLE 7: Manipulate the results you generated in
Example 6 to determine the number of items in a set that
possess at least one of the k properties maintained by the set.
|
EXAMPLE 8: Now apply the Inclusion-Exclusion Principle to
the problem of derangements:
|
In an apartment complex with k mailboxes, how
many ways can a mail carrier distribute k letters,
one addressed to each letter box, such that no
letter is placed in the correct box? Each of these is
called a derangement.
Recall that our goal was to efficiently determine the
number of elements in a set that possess none of a
specified list of properties or characteristics. We
began with several examples to generate patterns
that led to a generalization. Today we review the
generalization, suggest an extension, and use the
I-E P to solve a problem.
The notation we introduced last time included the use of a
capital letter (for example, C) to represent a property under
consideration. To represent the number of items or elements
having the property, we surrounded the capital letter with vertical
slashes (for exampe, |C|). We used a slash over the top of the
letter to represent the complement of the property. [For this web
page, we use a tilda (~) to represent the complement.] So ~C is
the property "not property C."
Through consideration of special cases and the illustrative use
of Venn diagrams, we developed the Inclusion-Exclusion
Principle to be
|~X(1) ^ ~X(2) ^ . . . ^ ~X(n)| = |S| - sigma(i,i,n;|X(i)|) +
sigma[j,1,n; sigma(i,j+1,n;|X(j) ^ X(i)|)] - . . . + (-1)^n|X(1) ^
X(2) ^ . . . X(n)|.
where S represents the entire set of items, each of which
possesses from none to all of the properties X(i), i = 1,2,...,n.
If we remove from S all items possessing none of the specified
properties, we are left with items that possess at least one of
the properties. This may be a useful corollary for application.
Symbolically we have
|X(1) U X(2) U . . . U X(n)| = |S| - |~X(1) + ~X(2) + . . . +
~X(n)| = sigma(i,i,n;|X(i)|) - sigma[j,1,n; sigma(i,j+1,n;|X(j)
^ X(i)|)] + . . . + (-1)^(n+1)|X(1) ^ X(2) ^ . . . X(n)|.
In the next section we apply the I-E P to a condition called a
derangement, requiring us to count the ways that "no
properties hold."
Here is a context representing the need to determine how many
derangements there are for a specified number of objects:
In an apartment complex with k mailboxes, how
many ways can a mail carrier distribute k letters,
one addressed to each letter box, such that no
letter is placed in the correct box? Each such
distribution scheme is called a derangement.
We begin by determining the number of derangements for
specific values of k, seeking to identify patterns in our
calculations that may lead to a conjecture for a general
representation for the number of derangements of n items.
Let us refer to a letter by a number and to a mailbox by a
number. Our task is to determine the number of ways to pair
letters and boxes so that no letter numbers match box numbers.
If k = 1, there are no ways to derange the letter, for there is one
letter to place in one box. If k = 2, we may place letter #2 in box
#1 and letter #1 in box #2, that being the only derangement.
When we have three letters, there are 3! = 6 total ways to
distribute them. We now write the letter numbers in the order
they are delivered, such as 1 3 2, indicating letter #1 is
delivered to box #1, letter #3 is delivered to box #2, and letter
#2 is delivered to box #3. The 6 possible distributions for 3
letters are
1 2 3 1 3 2
2 1 3 2 3 1
3 1 2 3 2 1
The schemes 2 3 1 and 3 1 2 are the only derangements of
three letters.
Summarizing our results thus far, using D(n) to represent the
number of derangements of n letters, we have D(1) = 0, D(2) =
1, and D(3) = 2. Any guesses on D(4)? Let's find out what it is.
We know there are 4! = 24 ways to distribute the 4 letters.
Rather than list the 24 cases, let us consider how the I-E P may
help us. We seek the number of ways to place the numbers in
the set {1,2,3,4} in line such that no value occurs in its natural
position. Let X(1) represent the property that 1 occurs in its
natural position when 1,2,3,4 are permuted. Then |X(1)| = (1)*3!.
The 1 represents the 1 way to place the 1 in its natural position
and the 3! shows the number of ways to permute the remaining
3 values. Note that we are not considering whether any of 2,3,4
wind up in their respective natural positions. We could argue
similarly that |X(2)| = |X(3)| = |X(4)|. Therefore, there are 4*3!
ways for a value to occur in its natural position.
What about |X(1) ^ X(2)|? Again there is 1 way to place 1,2 in
their natural order, and then 2! ways to place the remaining
values. This will be true for any pair of values we wish to restrict
to their natural positions. How many pairs are there? This is just
C(4,2) = 6. Therefore, there are C(4,2)*2! ways for two values to
simultaneously occur in their natural positions.
And for |X(1) ^ X(2) ^ X(3)|? Again there is 1 way to place 1,2,3
in their natural order, and then 1! way to place the remaining
value. This will be true for any set of three values we wish to
restrict to their natural positions. How many 3-element sets are
there? This is just C(4,3) = 4. Therefore, there are C(4,3)*1!
ways for three values to simultaneously occur in their natural
positions.
Finally, |X(1) ^ X(2) ^ X(3) ^ X(4)| = 1, for there is only one way
for all 4 values to be in their natural positions.
Now apply the I-E P:
|~X(1) ^ ~X(2) ^ ~X(3) ^ X(4)| = 4! - 4(3!) + 6(2!) - 4(1!) + 1 = 9.
In words, using the I-E P, we are suggesting that to determine
the number of derangements of the values 1,2,3,4, first calculate
the number of permutations of those values (4!), subtract the
number of ways to keep at least one element in its natural
position, add back the number of ways to keep at least two
values in their natural positions, subtract the number of ways to
keep at least three values in their natural positions, and finally
add back the number of ways to keep all values in their natural
positions.
We can rewrite the right side of the above equation to better
express the general result:
D(4) = |~X(1) ^ ~X(2) ^ ~X(3) ^ X(4)| = 4! - 4(3!) + 6(2!) -
4(1!) + 1
=C(4,0)*4! - C(4,1)*3! + C(4,2)*2! - C(4,3)*1! + C(4,4)*0!
=[4!/(0!4!)]*4! - [4!/(1!3!)]*3! + [4!/(2!2!)]*2! - [4!/(3!1!)]*1!
+ [4!/(4!0!)]*0!
=4!/0! - 4!/1! + 4!/2! - 4!/3! + 4!/4!
=4![1/0! - 1/1! + 1/2! - 1/3! + 1/4!]
=4![1 - 1/1! + 1/2! - 1/3! + 1/4!]
If we begin with n objects rather than 4, we can argue in a
similar way that
D(n) = n![1 - 1/1! + 1/2! - 1/3! + . . . (-1)^n*1/n!]
determines the number of derangements of n items.
Derangement에 관하여는 제 4주 4 강의를
참고하기 바랍니다.
|








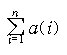 .
.